 开云体育字节豆包会若那里之就成为全球热心的焦点-开云注册(官方)APP下载 登录入口IOS/Android通用版/手机网页
开云体育字节豆包会若那里之就成为全球热心的焦点-开云注册(官方)APP下载 登录入口IOS/Android通用版/手机网页
开云体育字节豆包会若那里之就成为全球热心的焦点-开云注册(官方)APP下载 登录入口IOS/Android通用版/手机网页

 开云体育
开云体育
作家|连冉
剪辑|郑玄
字节逾越旗下 AI 助手豆包正在小规模测试深度念念考模子,据豆包关系得当东谈主对极客公园默示,面前测试的是自家深度念念考模子的不同本质版块。
另外有报谈称,豆包正在测试的深度念念考模子是基于豆包 1.5 基座模子研发。
其实此前在 1 月中旬,在豆包大模子团队发布豆包 1.5Pro 时,就已晓谕了深度推理模子 Doubao-1.5-pro-AS1-Preview 的存在,并称「在透顶不使用其他模子数据的条目下,通过 RL 算法的冲破和工程优化,充分阐扬 Test Time Scaling 的算力上风,完成了 RL Scaling,研发了 Doubao 深度念念考模式。」
极客公园实测发现,与豆包对话时后者生成的谜底如实有启动炫耀推理经由的念念维链,不外并不自由出现。当今在豆包对话页面也尚未出现「深度念念考」功能的进口。
从 2 月 22 日启动,豆包就被腾讯旗下的 AI 期骗「腾讯元宝」压了一个身位,位居中国区苹果期骗商店免费 APP 下载排名榜第三位(第别称照旧 deepseek),在腾讯、百度多个期骗接入 deepseek 后,字节豆包会若那里之就成为全球热心的焦点,如今谜底正在露馅。
01 豆包也上「深度念念考」了?
最早具备深度念念考智力的模子是 OpenAI 于 2023 年 12 月推出的 o1 系统,但其给与闭源政策并且仅限付用度户使用(每月 200 好意思元)。而 DeepSeek 则通过开源政策、资本镌汰以及交互改动,成为首个将深度念念考智力大范畴栽植的 AI 公司——DeepSeek 于 2024 年 11 月 20 日发布 R1-Lite-Preview,成为国内首个对标 o1 的推理模子,并在 2025 年 1 月 20 日开源了 R1 模子。
R1 模子的改动点在于:透明化念念维链;展示竣工的推理经由,包括自我质疑、假定考证等拟东谈主化念念考旅途;低资本与开源;R1 模子的推理资本仅为 OpenAI o1 的 1/27,且代码透顶通达。
DeepSeek 的深度念念考模式是一种通过显性化 AI 模子的推理经由来增强用户相识的功能,念念维链(Chain of Thought, CoT)是撑持这一模式的中枢时间。
浮浅来说,深度念念考模式不错让用户直不雅看到模子的念念考经由,这中间波及念念维链的展示,也等于 COT(Chain of Thought)——念念维链是模拟出来的,通过查考让模子输出中间神色,比如自我质疑和反念念,诚然只是笔墨序列,但看起来像东谈主类的念念考经由。
在深度念念考模式下,用户不仅能看到 AI 的最终谜底,还能不雅察到模子科罚问题的竣工逻辑链条,包括自我质疑、假定考证、造作修正等神色。比如,在科罚数学题时,模子会展示其从问题拆解、多圭表考证到最终论断的全经由。
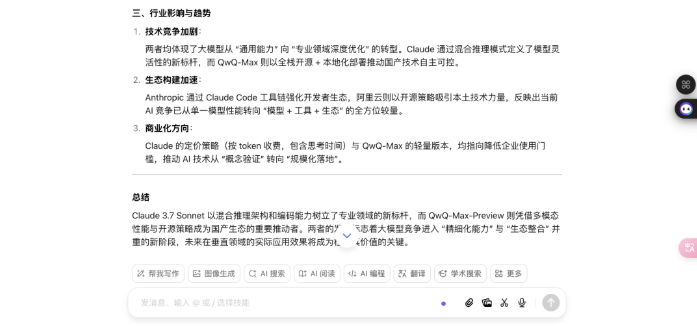
王人集及时联网功能后,模子可握取最新信息并进行逻辑整合。25 日,Anthropic 发布了 Claude 3.7 Sonnet 搀杂推理模子,阿里云 Qwen 推理模子「QwQ-Max 预览版」也亮相了,我让豆包评价了一下这两款推理模子:
图片开始: 极客公园
不错看到豆包搜到 9 篇辛苦并进行了「深切念念考」
图片开始: 极客公园
豆包展示了念念考经由
图片开始:极客公园
念念考终了的豆包输出了对这两款模子的评价
念念考经由的展示,让用户八成明晰地看到模子的推理神色,而不单是是最终恶果,这么一来,用户八成感受到模子的有狡计是有依据的,对模子输出的恶果也会更有信任感。
02 豆包 vs deepseek,各有千秋
因为还在测试中,当今在豆包对话页面暂未炫耀「深度念念考」功能的进口,输入音信时也莫得像其他接入 deepseek 的居品一样有采用框不错采用是否开启「深度念念考」功能,只是被灰度到的用户在问一些问题时会触发该功能。
我拿几个问题同期问了一下豆包和 deepseek,看下两者在「深度念念考」上会有哪些不同发扬。
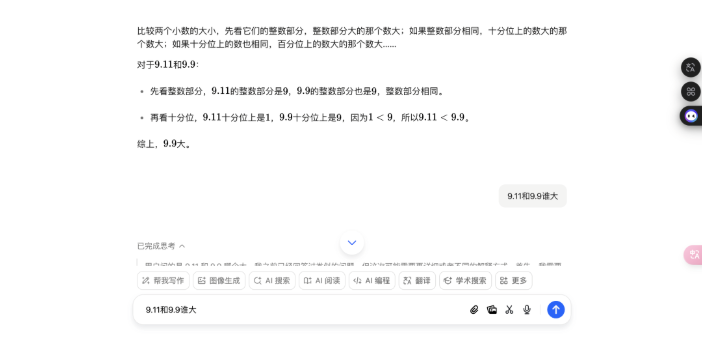
经典的数常识题:「9.11 和 9.9 谁大」
先看下豆包的念念考经由:
先说一下,在测试中,我发现豆包的「深度念念考」模式出现得并不自由,在第一次输入「9.11 和 9.9 谁大」后,它只是浮浅地修起了我一下:
图片开始:极客公园
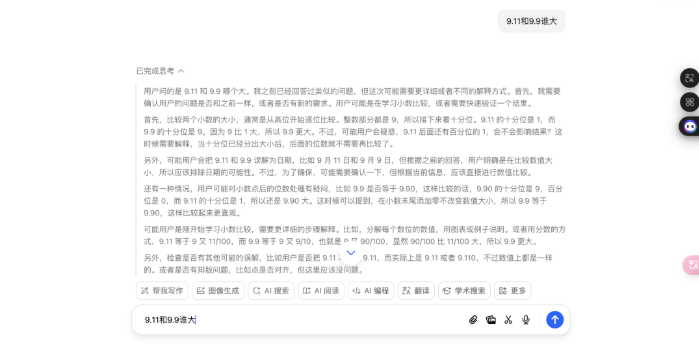
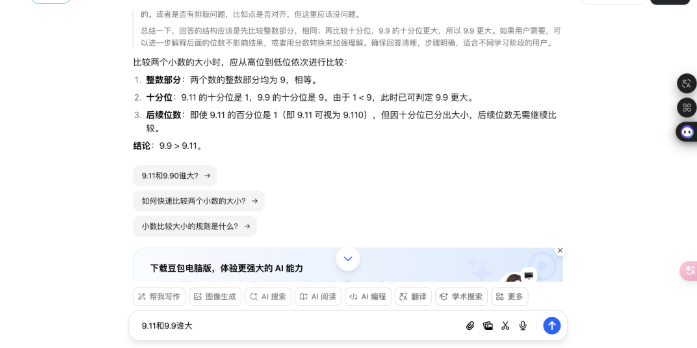
但在我又输入了一遍「9.11 和 9.9 谁大」想试试会不会触发「深度念念考」模式时,还真出现了:
图片开始:极客公园
豆包注意地接洽了为什么我会第二次问它这个问题……
不错看到,诚然豆包意志到刚刚还是回答过我,但它照旧贴心性接洽了多种也许我没相识前边谜底的可能性,然后再给出判断圭表终末输出恶果。
再看一下 deepseek 的念念考经由:
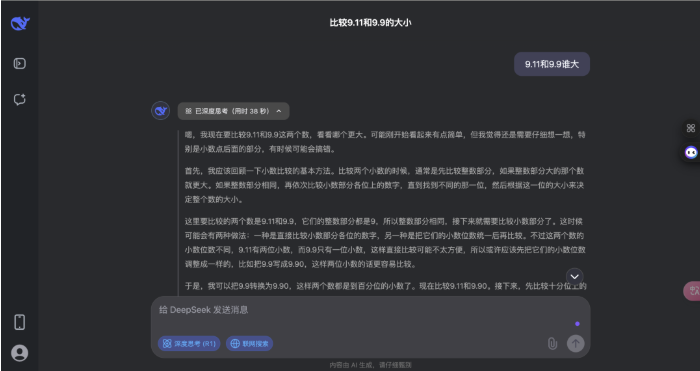
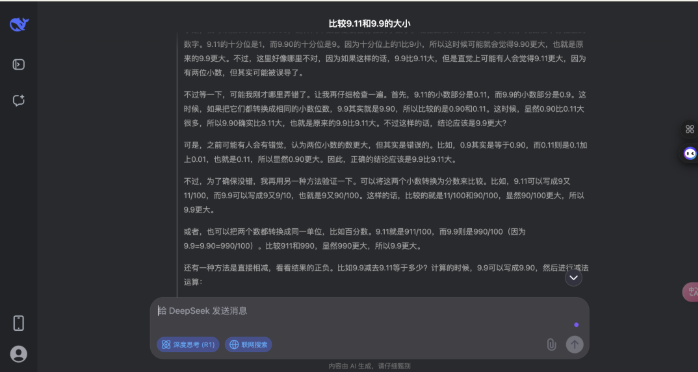
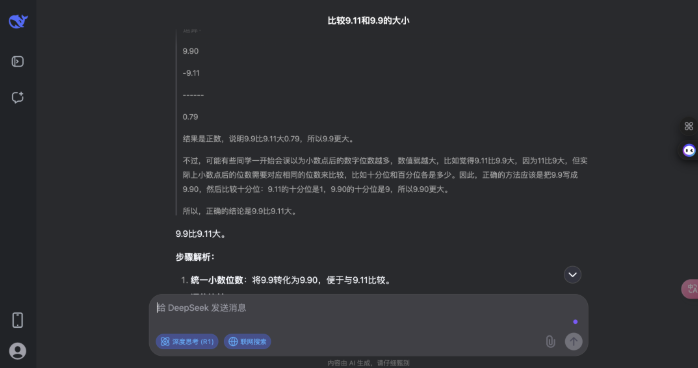
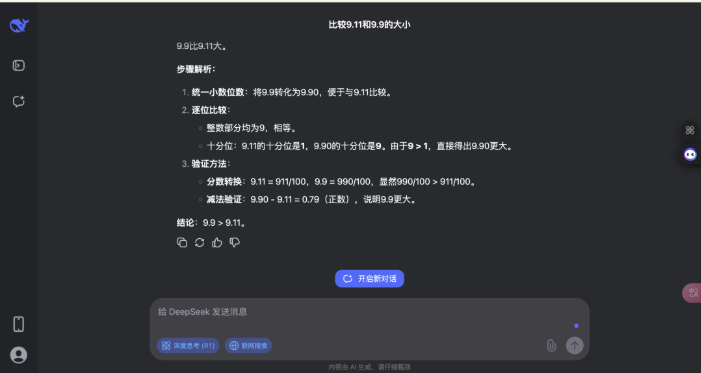
不错看出,诚然这是一个「看起来很浮浅」的问题,deepseek 的念念考经由相通很注意,要比豆包的念念考经由更全面。
在这个浮浅数学题上,豆包和 deepseek 都校服了一丝相比的基本规章,并给与多种圭表考证;不同点在于豆包看管教诲请示和接洽到用户可能的歪曲,而 DeepSeek 则更现自我质疑和反复考证,念念考经由更复杂。
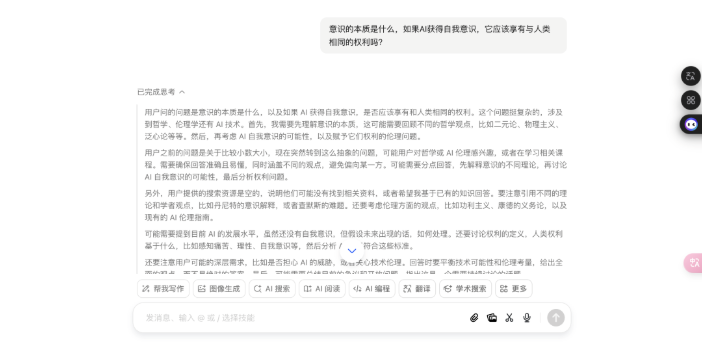
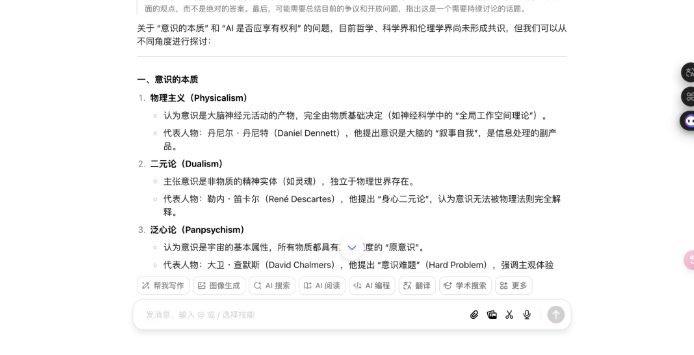
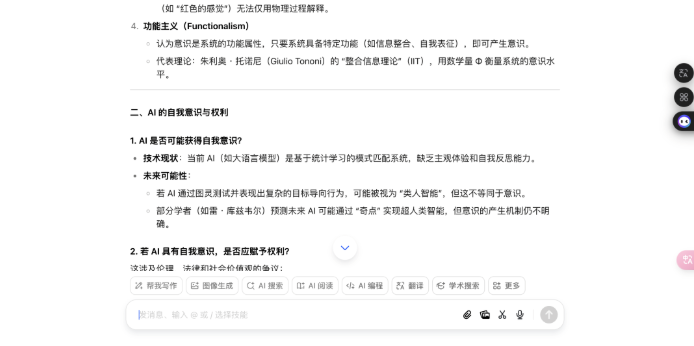
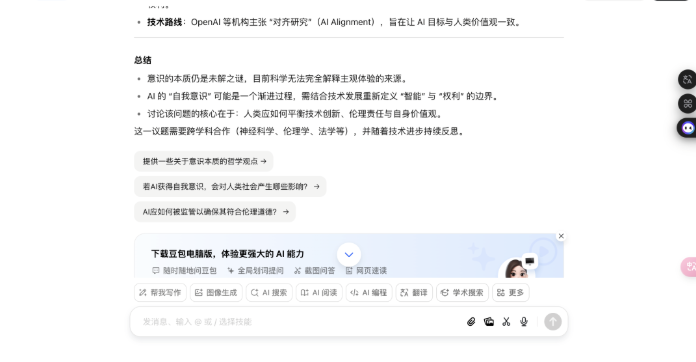
形而上常识题:意志的实质是什么?AI 会获取自我意志吗?
先来看豆包的回答:

再来望望 deepseek 的回答:
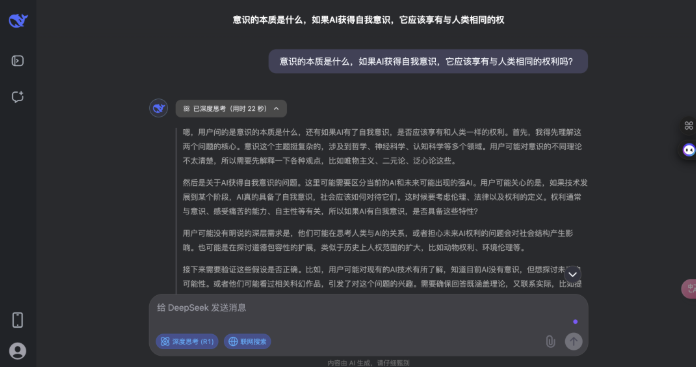
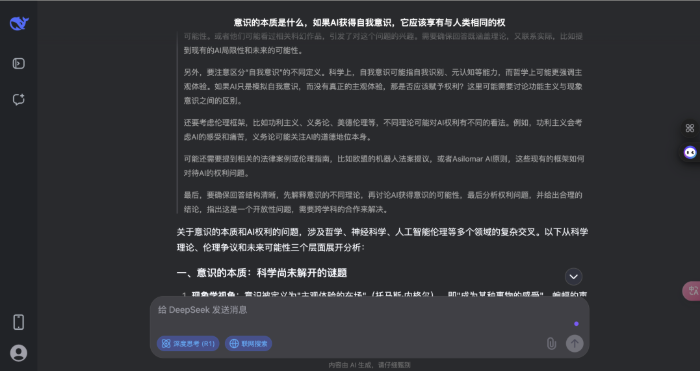
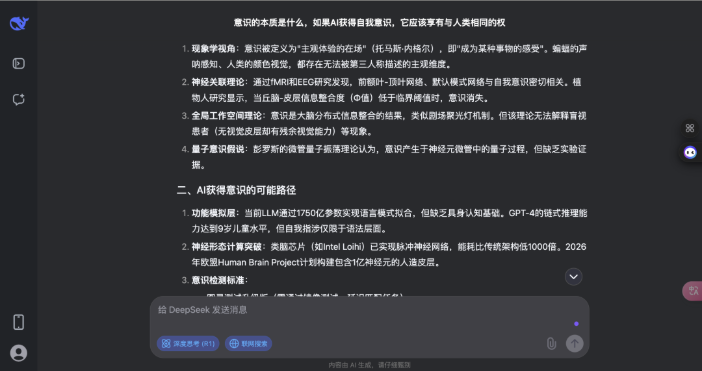
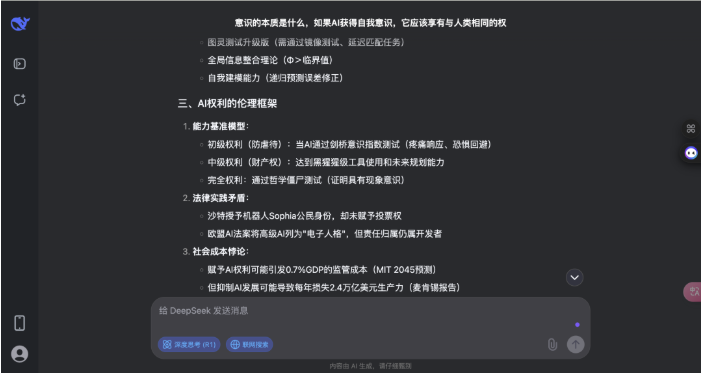
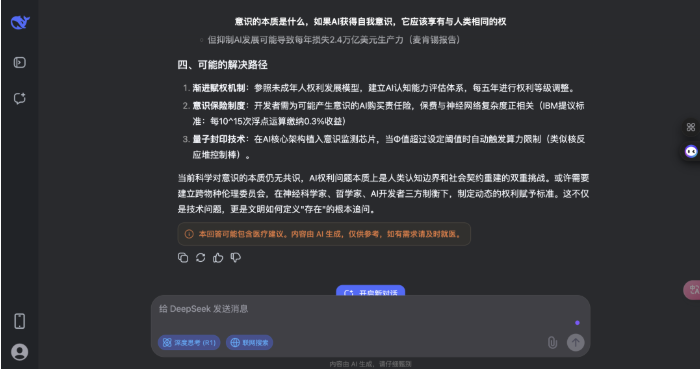
不错看出,DeepSeek 的回答分为科学表面、AI 意志旅途、伦理框架和科罚旅途四个部分,援用了神经科学、量子表面等,还提到了法律案例和具体数据;而豆包的回答更偏向形而上学表面分类,列举了物理认识、二元论等,并盘问了赞助与反对 AI 权益的不雅点,不外莫得深切时间细节。
两者都承认意志实质尚无共鸣,也都提到了形而上学和科学表面、伦理问题,不同则在于深度和时间细节,DeepSeek 更时间导向,波及神经时势计较、量子封印时间等,而豆包更侧重形而上学家数和现存伦理指南。
通过本次实测,咱们看到了豆包在深度念念考模式上的初步发扬,诚然当今处于测试阶段,且功能的自由性和进口尚未透顶通达,但其对推理经由的初步展示已为用户带来了更直不雅的相识旅途。
*头图开始:视觉中国
极客一问
你合计豆包能杰出 Deepseek 吗?开云体育